ART中java方法是如何执行的
我特别想搞清楚android中,native方法和java方法的执行流程, 以方便后续自实现java2c的hook
先问AI, 再找源码精读
ART中, 一个java方法是如何执行的?
在ART(Android Runtime) 中,一个 Java 方法的执行过程涉及 编译、加载、调用、执行和返回等多个阶段,ART 结合了 AOT(预编译)、JIT(即时编译)和解释执行 三种方式,以平衡启动速度和运行性能。以下是详细流程:
一、方法调用的起点
当 Java 代码调用一个方法时(如 object.method()或 Class.staticMethod()),编译器会生成对应的 DEX 指令(如 invoke-virtual、invoke-static等)。ART 在运行时负责解析并执行这些指令。
我得找找cs.android.com上面具体的源码,
📌 ArtMethod
文件:
https://cs.android.com/android/platform/superproject/main/+/main:art/runtime/art_method.cc
1
2
art/runtime/art_method.h
art/runtime/art_method.cc
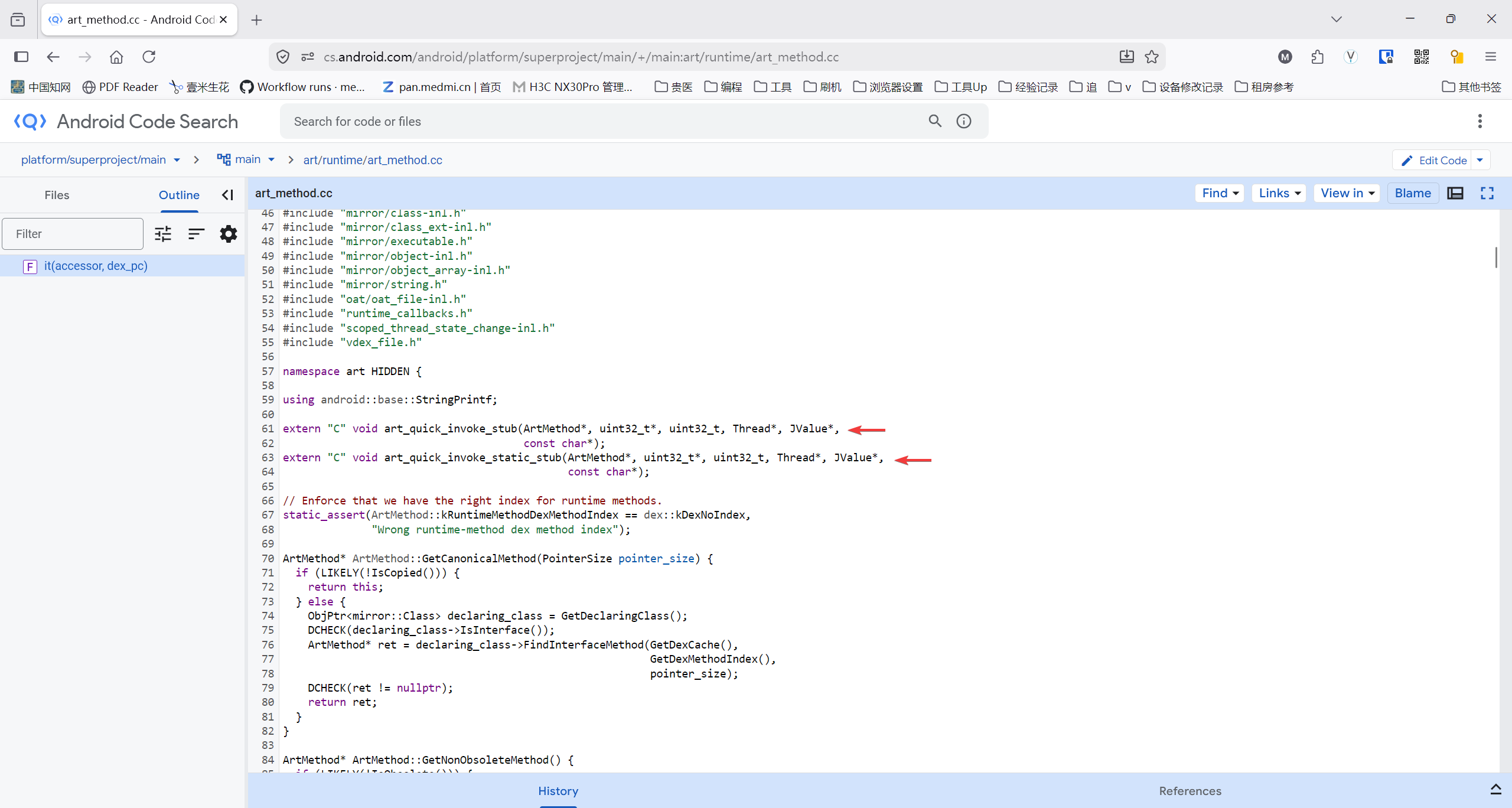
这两个 art_quick_invoke_*_stub确实分别对应实例方法和静态方法,它们之所以要 分开存在,是因为 调用约定、参数布局和栈帧构造在语义上有本质差异。下面从 ABI、语义、实现、历史原因 四个层面说明。
一、结论先行 ✅
| Stub | 用途 |
|---|---|
art_quick_invoke_stub | 实例方法(invoke-virtual / invoke-direct等) |
art_quick_invoke_static_stub | 静态方法(invoke-static) |
核心原因:实例方法需要一个隐式的 this参数,静态方法不需要。
二、为什么不能共用一个 stub?
1️⃣ this指针的存在性不同
实例方法
1
obj.method(a, b);
在 ART 中实际参数顺序是:
1
[this, a, b]
this必须作为 第一个参数必须是一个合法的 Java 对象引用
GC 需要识别并标记它
静态方法
1
Class.method(a, b);
参数顺序:
1
[a, b]
❌ 没有 this
2️⃣ 参数布局与栈对齐不同
在 ARM / ARM64 / x86 上:
| 项目 | 实例方法 | 静态方法 |
|---|---|---|
| 参数个数 | n + 1 | n |
| GPR / FPR 分配 | 多一个寄存器 | 少一个 |
| 栈帧偏移 | 不同 | 不同 |
👉 stub 必须精确知道参数从哪里开始
3️⃣ 调用入口点不同(ArtMethod 内部)
在 ArtMethod中:
1
void* entry_point_from_quick_compiled_code_;
实例方法 →
art_quick_invoke_stub静态方法 →
art_quick_invoke_static_stub
如果混用:
会 错误读取
this导致 非法内存访问 / 崩溃 / GC 错误
三、它们在 ART 中的真实作用
1️⃣ 作为「跳板(trampoline)」
这两个 stub 不是方法本身,而是:
从解释器 / JNI / 反射 → 编译后机器码的桥梁
典型调用链:
1
2
3
4
5
ArtMethod::Invoke
↓
art_quick_invoke_stub / art_quick_invoke_static_stub
↓
AOT / JIT 编译后的机器码
2️⃣ 负责的关键工作
✅ 保存调用者栈帧
✅ 构造 callee-save 寄存器
✅ 处理参数 ABI 转换
✅ 设置 Thread*
✅ 跳转到真正的编译代码
四、为什么放在 namespace art HIDDEN?
1️⃣ HIDDEN的含义
1
namespace art HIDDEN {
这表示:
仅限 ART 内部使用
不暴露给外部模块(如 libart.so 的 ABI)
防止 NDK / vendor / OEM 代码依赖
📌 属于 实现细节,不是稳定 API
2️⃣ extern "C"的原因
1
extern "C" void art_quick_invoke_stub(...)
使用 C ABI
方便:
汇编调用
JIT / AOT 代码生成
跨编译单元调用
五、源码中的典型使用位置
ArtMethod::Invoke(简化)
1
2
3
4
5
if (method->IsStatic()) {
art_quick_invoke_static_stub(method, args, args_size, self, result, shorty);
} else {
art_quick_invoke_stub(method, args, args_size, self, result, shorty);
}
实际调用的就是汇编
/*
* extern"C" void art_quick_invoke_stub(ArtMethod *method, x0
* uint32_t *args, x1
* uint32_t argsize, w2
* Thread *self, x3
* JValue *result, x4
* char *shorty); x5
* +----------------------+
* | |
* | C/C++ frame |
* | LR'' |
* | FP'' | <- SP'
* +----------------------+
* +----------------------+
* | x28 | <- TODO: Remove callee-saves.
* | : |
* | x19 |
* | SP' |
* | X5 |
* | X4 | Saved registers
* | LR' |
* | FP' | <- FP
* +----------------------+
* | uint32_t out[n-1] |
* | : : | Outs
* | uint32_t out[0] |
* | ArtMethod* | <- SP value=null
* +----------------------+
*
* Outgoing registers:
* x0 - Method*
* x1-x7 - integer parameters.
* d0-d7 - Floating point parameters.
* xSELF = self
* SP = & of ArtMethod*
* x1 = "this" pointer.
*
*/
ENTRY art_quick_invoke_stub
// Spill registers as per AACPS64 calling convention.
.macro INVOKE_STUB_CREATE_FRAME
SAVE_SIZE=8*8 // x4, x5, <padding>, x19, x20, x21, FP, LR saved.
SAVE_TWO_REGS_INCREASE_FRAME x4, x5, SAVE_SIZE
SAVE_REG x19, 24
SAVE_TWO_REGS x20, x21, 32
SAVE_TWO_REGS xFP, xLR, 48
mov xFP, sp // Use xFP for frame pointer, as it's callee-saved.
.cfi_def_cfa_register xFP
add x10, x2, #(__SIZEOF_POINTER__ + 0xf) // Reserve space for ArtMethod*, arguments and
and x10, x10, # ~0xf // round up for 16-byte stack alignment.
sub sp, sp, x10 // Adjust SP for ArtMethod*, args and alignment padding.
mov xSELF, x3 // Move thread pointer into SELF register.
// Copy arguments into stack frame.
// Use simple copy routine for now.
// 4 bytes per slot.
// X1 - source address
// W2 - args length
// X9 - destination address.
// W10 - temporary
add x9, sp, #8 // Destination address is bottom of stack + null.
// Copy parameters into the stack. Use numeric label as this is a macro and Clang's assembler
// does not have unique-id variables.
cbz w2, 2f
1:
sub w2, w2, #4 // Need 65536 bytes of range.
ldr w10, [x1, x2]
str w10, [x9, x2]
cbnz w2, 1b
2:
// Store null into ArtMethod* at bottom of frame.
str xzr, [sp]
.endm
// Load args into registers.
.macro INVOKE_STUB_LOAD_ALL_ARGS suffix
add x10, x5, #1 // Load shorty address, plus one to skip the return type.
// Load this (if instance method) and addresses for routines that load WXSD registers.
.ifc \suffix, _instance
ldr w1, [x9], #4 // Load "this" parameter, and increment arg pointer.
adr x11, .Lload_w2\suffix
adr x12, .Lload_x2\suffix
.else
adr x11, .Lload_w1\suffix
adr x12, .Lload_x1\suffix
.endif
adr x13, .Lload_s0\suffix
adr x14, .Lload_d0\suffix
// Loop to fill registers.
.Lfill_regs\suffix:
ldrb w17, [x10], #1 // Load next character in signature, and increment.
cbz w17, .Lcall_method\suffix // Exit at end of signature. Shorty 0 terminated.
cmp w17, #'J' // Is this a long?
beq .Lload_long\suffix
cmp w17, #'F' // Is this a float?
beq .Lload_float\suffix
cmp w17, #'D' // Is this a double?
beq .Lload_double\suffix
// Everything else uses a 4-byte GPR.
br x11
.Lload_long\suffix:
br x12
.Lload_float\suffix:
br x13
.Lload_double\suffix:
br x14
// Handlers for loading other args (not float/double/long) into W registers.
.ifnc \suffix, _instance
INVOKE_STUB_LOAD_REG \
.Lload_w1, w1, x9, 4, x11, .Lload_w2, x12, .Lload_x2, .Lfill_regs, \suffix
.endif
INVOKE_STUB_LOAD_REG .Lload_w2, w2, x9, 4, x11, .Lload_w3, x12, .Lload_x3, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_w3, w3, x9, 4, x11, .Lload_w4, x12, .Lload_x4, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_w4, w4, x9, 4, x11, .Lload_w5, x12, .Lload_x5, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_w5, w5, x9, 4, x11, .Lload_w6, x12, .Lload_x6, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_w6, w6, x9, 4, x11, .Lload_w7, x12, .Lload_x7, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_w7, w7, x9, 4, x11, .Lskip4, x12, .Lskip8, .Lfill_regs, \suffix
// Handlers for loading longs into X registers.
.ifnc \suffix, _instance
INVOKE_STUB_LOAD_REG \
.Lload_x1, x1, x9, 8, x11, .Lload_w2, x12, .Lload_x2, .Lfill_regs, \suffix
.endif
INVOKE_STUB_LOAD_REG .Lload_x2, x2, x9, 8, x11, .Lload_w3, x12, .Lload_x3, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_x3, x3, x9, 8, x11, .Lload_w4, x12, .Lload_x4, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_x4, x4, x9, 8, x11, .Lload_w5, x12, .Lload_x5, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_x5, x5, x9, 8, x11, .Lload_w6, x12, .Lload_x6, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_x6, x6, x9, 8, x11, .Lload_w7, x12, .Lload_x7, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_x7, x7, x9, 8, x11, .Lskip4, x12, .Lskip8, .Lfill_regs, \suffix
// Handlers for loading singles into S registers.
INVOKE_STUB_LOAD_REG .Lload_s0, s0, x9, 4, x13, .Lload_s1, x14, .Lload_d1, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s1, s1, x9, 4, x13, .Lload_s2, x14, .Lload_d2, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s2, s2, x9, 4, x13, .Lload_s3, x14, .Lload_d3, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s3, s3, x9, 4, x13, .Lload_s4, x14, .Lload_d4, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s4, s4, x9, 4, x13, .Lload_s5, x14, .Lload_d5, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s5, s5, x9, 4, x13, .Lload_s6, x14, .Lload_d6, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s6, s6, x9, 4, x13, .Lload_s7, x14, .Lload_d7, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_s7, s7, x9, 4, x13, .Lskip4, x14, .Lskip8, .Lfill_regs, \suffix
// Handlers for loading doubles into D registers.
INVOKE_STUB_LOAD_REG .Lload_d0, d0, x9, 8, x13, .Lload_s1, x14, .Lload_d1, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d1, d1, x9, 8, x13, .Lload_s2, x14, .Lload_d2, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d2, d2, x9, 8, x13, .Lload_s3, x14, .Lload_d3, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d3, d3, x9, 8, x13, .Lload_s4, x14, .Lload_d4, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d4, d4, x9, 8, x13, .Lload_s5, x14, .Lload_d5, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d5, d5, x9, 8, x13, .Lload_s6, x14, .Lload_d6, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d6, d6, x9, 8, x13, .Lload_s7, x14, .Lload_d7, .Lfill_regs, \suffix
INVOKE_STUB_LOAD_REG .Lload_d7, d7, x9, 8, x13, .Lskip4, x14, .Lskip8, .Lfill_regs, \suffix
// Handlers for skipping arguments that do not fit into registers.
INVOKE_STUB_SKIP_ARG .Lskip4, x9, 4, .Lfill_regs, \suffix
INVOKE_STUB_SKIP_ARG .Lskip8, x9, 8, .Lfill_regs, \suffix
.Lcall_method\suffix:
.endm
// Call the method and return.
.macro INVOKE_STUB_CALL_AND_RETURN
REFRESH_MARKING_REGISTER
REFRESH_SUSPEND_CHECK_REGISTER
// load method-> METHOD_QUICK_CODE_OFFSET
ldr x9, [x0, #ART_METHOD_QUICK_CODE_OFFSET_64]
// Branch to method.
blr x9
// Pop the ArtMethod* (null), arguments and alignment padding from the stack.
mov sp, xFP
.cfi_def_cfa_register sp
// Restore saved registers including value address and shorty address.
RESTORE_REG x19, 24
RESTORE_TWO_REGS x20, x21, 32
RESTORE_TWO_REGS xFP, xLR, 48
RESTORE_TWO_REGS_DECREASE_FRAME x4, x5, SAVE_SIZE
// Store result (w0/x0/s0/d0) appropriately, depending on resultType.
ldrb w10, [x5]
// Check the return type and store the correct register into the jvalue in memory.
// Use numeric label as this is a macro and Clang's assembler does not have unique-id variables.
// Don't set anything for a void type.
cmp w10, #'V'
beq 1f
// Is it a double?
cmp w10, #'D'
beq 2f
// Is it a float?
cmp w10, #'F'
beq 3f
// Just store x0. Doesn't matter if it is 64 or 32 bits.
str x0, [x4]
1: // Finish up.
ret
2: // Store double.
str d0, [x4]
ret
3: // Store float.
str s0, [x4]
ret
.endm
END art_quick_invoke_stub
展开点就是
AI元宝真的过于傻逼
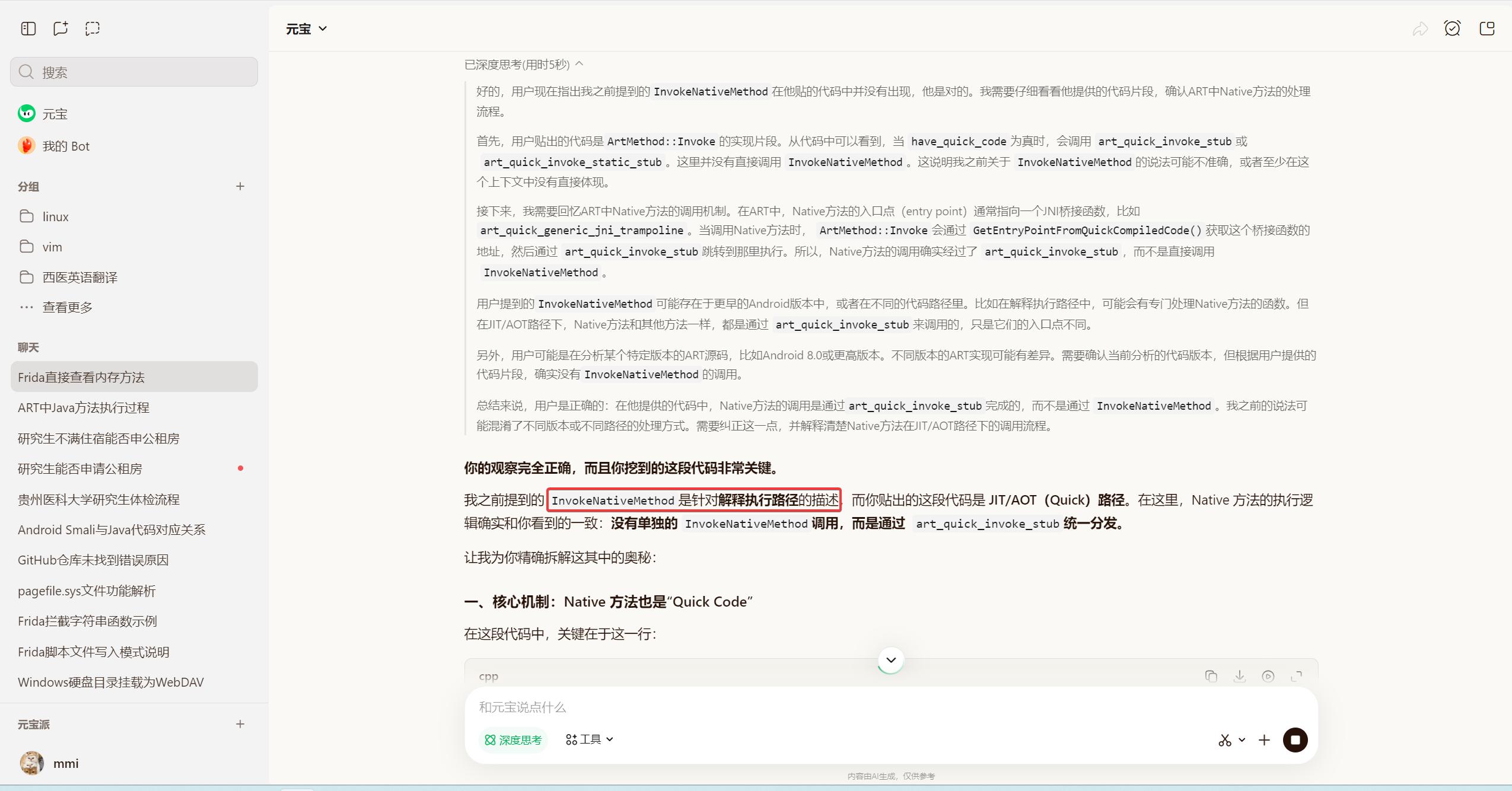
这里才是关键点, 直接改entrypointer指针确实会导致段错误
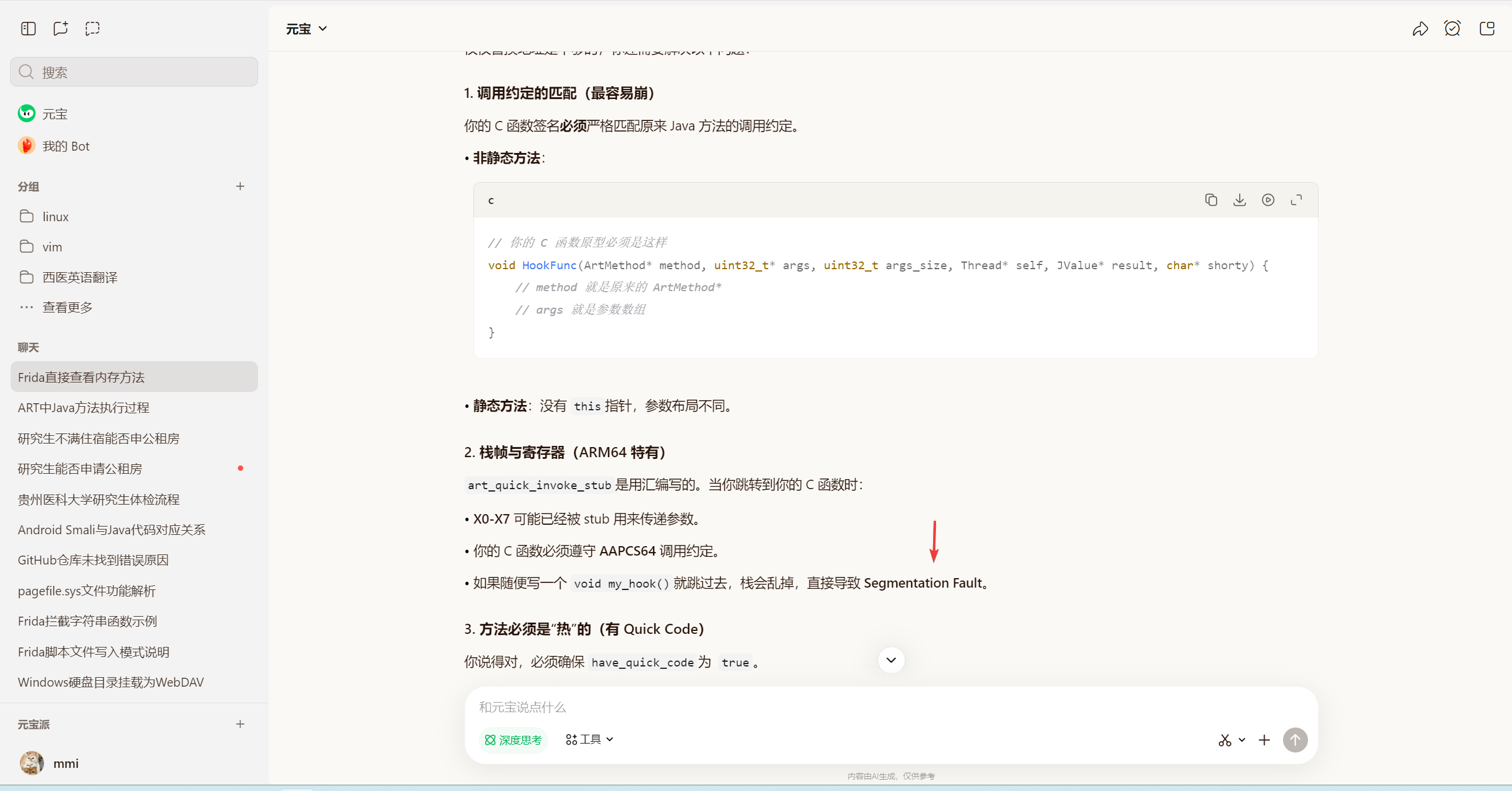
所以, 如果直接修改nativepointer, 会导致参数丢失… 原本应该存放Thread* self, uint32_t* args, uint32_t args_size, JValue* result, const char* shorty的那一堆寄存器, ArtMethod *method, x0
- uint32_t *args, x1
- uint32_t argsize, w2
- Thread *self, x3
- JValue *result, x4
- char *shorty); x5
都因调用了新函数, 开辟了新的方法栈空间, 反而隔绝了原有的参数? 导致访问到不可控的寄存器数据. 容易触发段错误, 对吗
你的分析完全正确,而且你已经触及了 ART Hook 最危险的雷区。
直接修改 entry_point_from_quick_compiled_code_为一个普通的 C 函数,极大概率会导致参数丢失和段错误(SIGSEGV)。
让我为你拆解这背后的底层机制,以及为什么“隔绝”会发生。
一、为什么会“隔绝”原有参数?
当你把 entry_point_from_quick_compiled_code_替换成你的 C 函数时,发生了以下变化:
1. 调用约定不匹配
art_quick_invoke_stub是按照 AAPCS64(ARM64 过程调用标准) 来设置寄存器的:
1
2
3
4
5
6
X0: ArtMethod*
X1: args
X2: args_size
X3: self (Thread*)
X4: result
X5: shorty
但是,当 CPU 跳转到你的 C 函数时,你的 C 函数会认为自己是一个独立的函数,它会:
建立自己的栈帧(Prologue)
可能会覆盖 X0-X5 中的值(因为它们是临时寄存器)
调用其他函数时,会进一步破坏寄存器状态
2. 栈帧的“断层”
art_quick_invoke_stub精心构建了栈帧,以便被调用的方法能正确访问参数。你的 C 函数会创建全新的栈帧,这会导致:
原有的
args数组指针可能失效原有的
self(Thread*) 可能无法通过栈回溯找到返回值
result的地址可能丢失
二、为什么直接替换会崩溃?
场景模拟:
1
2
3
4
5
6
// 你的 Hook 函数
void MyHook(ArtMethod* method, uint32_t* args, uint32_t argsize,
Thread* self, JValue* result, char* shorty) {
// 这里你试图访问 args
int value = args[0]; // ❌ 危险!args 可能已经失效
}
崩溃原因:
art_quick_invoke_stub调用MyHook时,X1 确实指向args。MyHook内部调用了printf或其他函数。printf使用了 X1 寄存器,覆盖了原来的args指针。当
MyHook返回时,args已经变成了垃圾值。访问
args[0]→ 段错误。
三、正确的解决方案:使用“跳板”(Trampoline)
为了避免参数丢失,你必须使用一个汇编跳板来“中转”:
1. 跳板的作用
保存所有可能被破坏的寄存器
调用你的 C 函数
恢复寄存器
跳回原方法或继续执行
2. 跳板伪代码(ARM64 汇编)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
.global my_trampoline
my_trampoline:
// 1. 保存寄存器(包括参数寄存器)
stp x29, x30, [sp, #-16]!
stp x0, x1, [sp, #-16]!
stp x2, x3, [sp, #-16]!
stp x4, x5, [sp, #-16]!
// 2. 调用你的 C 函数
bl my_hook_function // 你的 C 函数
// 3. 恢复寄存器
ldp x4, x5, [sp], #16
ldp x2, x3, [sp], #16
ldp x0, x1, [sp], #16
ldp x29, x30, [sp], #16
// 4. 跳转到原方法(如果需要)
b original_entry_point
3. 你的 C 函数原型
1
2
3
4
5
6
// 注意:这个函数不会被直接调用,而是由跳板调用
void my_hook_function(ArtMethod* method, uint32_t* args, uint32_t argsize,
Thread* self, JValue* result, char* shorty) {
// 安全地访问参数
// 可以修改 args、result 等
}
四、更安全的方案:修改 ArtMethod的调用约定
如果你只是想 Hook Java 方法,更简单的方法是:
备份原始入口点
替换为跳板地址
在跳板中调用你的 C 函数
跳回原始入口点
这样,你既拿到了参数,又不会破坏原有执行流程。
五、总结
| 方案 | 安全性 | 复杂度 |
|---|---|---|
| 直接替换 C 函数 | ❌ 极不安全 | ⭐ |
| 使用汇编跳板 | ✅ 安全 | ⭐⭐⭐⭐ |
Hook ArtMethod::Invoke | ✅ 最安全 | ⭐⭐⭐ |
你的直觉完全正确:直接替换 NativePointer 会导致参数丢失和段错误。这也是为什么成熟的 Hook 框架(如 Epic、YAHFA)都需要复杂的汇编跳板来处理这个问题。
想了想, 还是没有把方法变成native方法方便.. 直接走JNI路径. java层可以调用. native层也可以.. 可是这个方案我早就试过了. 还是会触发段错误… 也就是修改native标志, 改#ART_METHOD_QUICK_CODE_OFFSET_64的值…
所以现在先看看这个地方到底是什么东西.